ĐỀ TÀI KHOA HỌC KĨ THUẬT CỦA MÌNH & NHỮNG KIẾN THỨC XUNG QUANH NÓ
Tác giả: Học viên: Phan Trung Kiệt – Học viên khóa 2020-2023
Xin chào các thầy cô, các anh chị Hannah, và các bạn học viên. Mình là Kiệt, học viên khóa thứ nhất của câu lạc bộ. Trong bài viết này, mình muốn chia sẻ đến mọi người về đề tài của mình trong cuộc thi Khoa học kĩ thuật (KHKT) cấp Thành phố ở Đà Nẵng. Mặc dù đạt được giải Nhất trong cuộc thi nhưng mình lại không có cơ hội để tiếp tục ở cấp Quốc gia (ViSEF). ?
I. Giới thiệu
Vậy thật sự mình đã làm về những gì trong đề tài đó và tại sao mình lại chọn nó? Đề tài của mình là “Ứng dụng công nghệ nhận dạng để giám sát và hỗ trợ phát hiện bệnh trong việc trồng ngô”. Lần đầu mình tiếp xúc với Deep Learning là vào năm thứ 2 của mình ở câu lạc bộ. Cũng với cuộc thi KHKT, mình đã sử dụng công nghệ này cho việc nhận dạng trái cây để áp dụng vào việc bán hàng tự động. Vì cũng mới biết đến nên mình cảm thấy rất hứng thú và tò mò về mảng Deep Learning này.
Hiện nay, mình thấy ngô là một loại ngũ cốc đóng vai khá trò quan trọng đối với con người về nhiều mặt. Ngô là loại lương thực được trồng nhiều nhất trên thế giới. Tuy nhiên, dịch bệnh là một mối đe dọa vô cùng lớn đối với loại cây trồng này, nó sẽ khiến năng suất của ngô bị suy giảm và gây ảnh hưởng đến nền kinh tế nông nghiệp. Do vậy, mình quyết định tìm hiểu về những phương pháp phát hiện bệnh trên cây trồng thì thấy một số cách phân tích bệnh trong phòng thí nghiệm, khá là tốn thời gian và công sức. Đó cũng chính là lý do mình quyết định áp dụng công nghệ nhận dạng vào việc phát hiện bệnh trên lá cây ngô.
II. Có những cái gì trong đề tài này?
Để thực hiện dự án này, mình đã tìm hiểu về một số kiến thức mà trong đó có vài thứ mình chưa từng tiếp xúc qua trước đây. Trước hết phải kể đến Deep Learning, đây là thứ cốt lõi của dự án mình. Tiếp theo là tạo ứng dụng di động (Mobile app). Và cuối cùng đó chính là tạo API và đăng ký Cloud.
- Deep Learning
Đầu tiên, ta cùng đến với Deep Learning (Học sâu). Deep Learning là một công nghệ Machine Learning (Máy học) mà nó sẽ dạy cho máy tính những thứ tự nhiên đến với con người: học qua ví dụ (learn by example). Cụ thể hơn, máy tính sẽ được cung cấp một lượng lớn dữ liệu. Sau khi học qua nhiều lần từ bộ dữ liệu đó, hay còn gọi là quá trình huấn luyện mô hình (train model), máy tính sẽ dần có thể nhận biết được từng loại dữ liệu khác nhau.
- Ví dụ về một bộ dữ liệu chất lượng rượu vang đỏ:
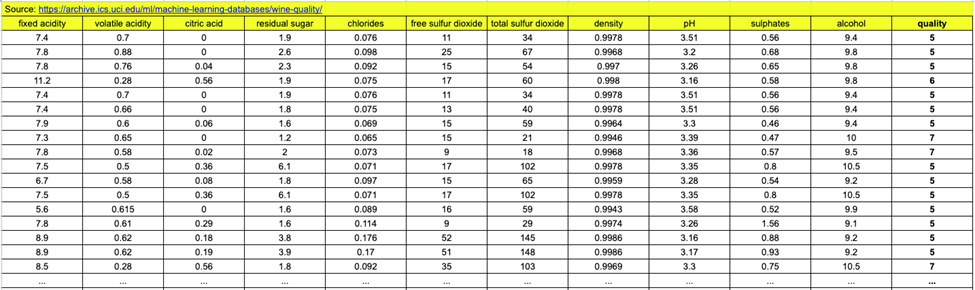
Với mỗi mẫu rượu, ta sẽ có các thông số (fixed acidity, volatile acidity, …, alcohol) và chất lượng (quality) của mẫu rượu đó (từ 0 đến 10). Sau khi huấn luyện mô hình bằng bộ dữ liệu này, máy tính sẽ có khả năng đánh giá được chất lượng của một mẫu rượu khi được cho 11 thông số đó.
- Bộ dữ liệu cũng có thể là hình ảnh. Đây là ví dụ về một bộ dữ liệu biển báo giao thông:
Source: https://pyimagesearch.com/2019/11/04/traffic-sign-classification-with-keras-and-deep-learning

Bộ dữ liệu bao gồm 62 loại biển báo khác nhau. Với mỗi loại biển báo, sẽ có một lượng lớn ảnh được chụp trong nhiều điều kiện khác nhau (ánh sáng, góc chụp,…). Cũng tương tự, máy tính sẽ có thể nhận biết được một trong 62 loại biển báo đó thông qua hình ảnh cung cấp sau khi được huấn luyện với bộ dữ liệu lớn này.
Tuy nhiên, mô hình dùng cho việc huấn luyện của 2 bài toán trên là không giống nhau. Với mỗi loại dữ liệu khác nhau, chúng ta sẽ sử dụng loại mô hình khác nhau để huấn luyện. Trong ví dụ đầu tiên, chúng ta có dạng dữ liệu đơn giản (bài toán đánh giá chất lượng rượu) nên có thể sử dụng Linear Regression (Hồi quy tuyến tính), các bạn có thể tham khảo thêm tại đây. Còn với ví dụ thứ hai, dạng dữ liệu là hình ảnh nên cần sử dụng những mô hình phức tạp hơn là Artificial Neural Network (Mạng nơ-ron nhân tạo), các bạn có thể tham khảo thêm tại đây.
→ Vậy là trong một bài toán nhận dạng, bên cạnh bộ cơ sở dữ liệu là một thứ vô cùng quan trọng thì mô hình cũng là thứ chúng ta cần chú ý. Trong đề tài này, mình đã sử dụng 5 mô hình khác nhau (DenseNet121, InceptionV3, ResNet50, VGG16, Xception) trong số nhiều mô hình của Keras để tìm ra mô hình phù hợp và tốt nhất.
→ Ngoài ra, tỉ lệ train/test cho bộ cơ sở dữ liệu cũng là yếu tố quan trọng. Nếu chọn được tỉ lệ phù hợp thì nó giúp chúng ta đánh giá được chính xác mức độ hiệu quả, khả năng nhận dạng của mô hình được huấn luyện. Mình đã thử nghiệm 2 tỉ lệ là 80/20 và 70/30 trong đề tài này.
- Thuật toán SLIC Segmentation
Mình sử dụng thuật toán Image Segmentation để làm gì?
Image Segmentation (Phân vùng ảnh) là một mảng trong Computer Vision (Thị giác máy tính) và Digital Image Processing (Xử lý ảnh kỹ thuật số), có thể được dùng cho việc nhóm những vùng ảnh có sự tương đồng với nhau.
- Đây là ví dụ một bức ảnh trước và sau khi được áp dụng các thuật toán Segmentation:
Source: https://www.v7labs.com/blog/image-segmentation-guide
Cũng như định nghĩa của nó, mình sử dụng để phân vùng mỗi bức ảnh. Một bức ảnh trong bộ cơ sở dữ liệu bao gồm nhiều phần khác nhau: vùng lá bệnh, vùng lá khoẻ, nền. Để tránh sự nhầm lẫn giữa lá ngô trong bức ảnh và những vật dễ gây nhiễu ở phông nền, mình đã sử dụng thuật toán này để có thể tăng được độ chính xác cho mô hình nhận dạng.

Và thuật toán Image Segmentation mà mình sử dụng trong đề tài lần này đó chính là SLIC (Simple Linear Iterative Clustering) Segmentation. Thuật toán này có thể phân một bức ảnh thành nhiều phần (hay còn gọi là Superpixels) dựa trên sự tương đồng về màu sắc và khoảng cách của chúng trong mặt phẳng hình ảnh.
Để dễ hiểu hơn, chúng ta cần 2 thông số chính để có thể áp dụng thuật toán SLIC Segmentation vào một bức ảnh bất kì, đó chính là K và m. K là số lượng superpixels xấp xỉ sau khi phân vùng ảnh. Còn m là khoảng cách không gian giữa các superpixels. Chúng ta có thể hình dung rõ hơn áp dụng thuật toán SLIC Segmentation cho cùng một bức ảnh với K = 15, m = 1, 5, 25, 50, 100 ta được 5 bức hình sau đây (từ trái sang phải):

Khi sử dụng thuật toán này để xử lý ảnh thì bộ dữ liệu thực chất là những superpixel được cắt ra từ những tấm ảnh gốc, không phải là nguyên một bức ảnh lá cây như các bài toán nhận dạng khác. Do đó, khi đưa vào thử nghiệm ta cần phải cắt ảnh rồi nhận dạng từng superpixel được cắt ra chứ không nên nhận dạng nguyên tấm ảnh.
→ Ta có thể thấy, khi m nhỏ thì những superpixel được cắt ra khá chính xác và phân được những thành phần khác nhau rất sát. Do vậy, những superpixel này có hình dạng rất khác với những cái còn lại (specific) nên model được train sẽ dễ bị overfitting. Còn khi m lớn, những superpixel được cắt ra không được chính xác lắm, mỗi superpixel dễ bị lẫn cả 2 thành phần trở lên, khiến model dễ bị nhầm lẫn.
→ Vậy nên mình đã quyết định chọn m = 5 (ví dụ bức hình thứ 2 là ảnh được cắt với m = 5), không quá nhỏ cũng không quá lớn. Còn đối với K, mình đã thử nghiệm với cả 3 giá trị 15, 20, 25 để tìm ra con số phù hợp nhất. Lý do mình không tiếp tục thử với những giá trị K lớn hơn là vì những superpixel được cắt ra cần phải label (phân loại) nên K càng lớn sẽ càng tốn nhiều thời gian để xử lý dữ liệu hơn.
→ Cuối cùng, có tất cả: 5(model) x 2(tỉ lệ train/test) x 3(giá trị K) = 30 model khác nhau được train. Để tim được mô hình phù hợp nhất trong số các model được train, mình đã xét các yếu tố sau: độ chính xác của model, độ ổn định trong khi được huấn luyện, độ phức tạp của model (thời gian nhận dạng/số phép tính).
- API và Cloud
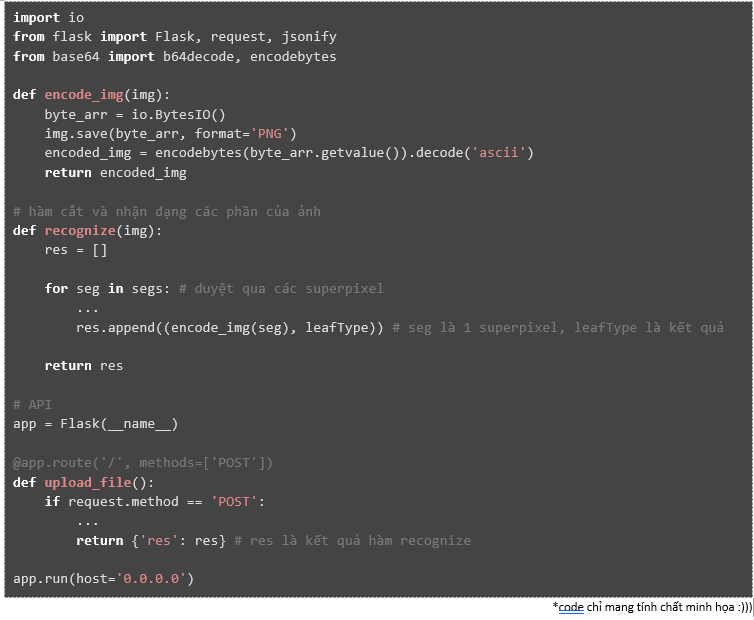
Trong đề tài này, mình đã sử dụng thư viện “flask” trong Python để xây dựng API, và cụ thể là RESTful API. Mục đích tạo ra API này là phục vụ cho việc nhận dạng ảnh chụp lá ngô.
API bao gồm 2 phần chính:
- Phần Deep Learning (sử dụng model phù hợp, ổn định, và có độ chính xác cao trong số tất cả các model được train để nhận dạng hình ảnh được cho).
- Phần nhận hình ảnh và trả về kết quả nhận dạng từ request (yêu cầu) của ứng dụng trên điện thoại.
Sau khi chọn được mô hình phù hợp, chúng ta sẽ tạo một hàm sử dụng thuật toán SLIC Segmentation để cắt thành nhiều superpixel rồi nhận dạng mỗi phần đó. Đây là code ví dụ cho cách sử dụng thuật toán SLIC Segmentation trong Python (thư viện scikit-image).
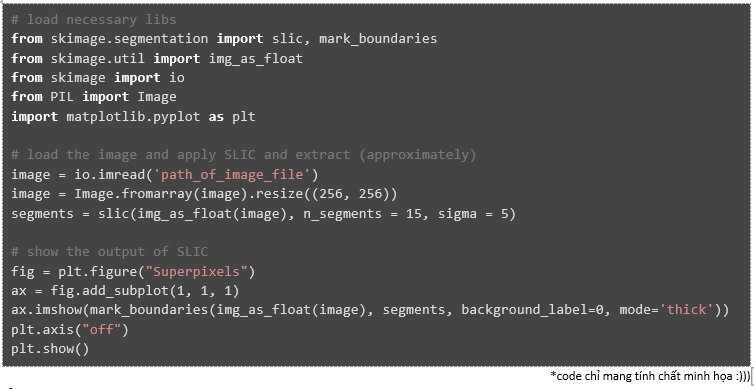
Ảnh trước và sau khi được áp dụng thuật toán SLIC Segmentation với K = 15 và m = 5:


Còn đối với việc sử dụng model được train để nhận dạng một ảnh bất kì thì ta có thể làm như sau (seg là một bức ảnh bất kì, ở đây là một superpixel được cắt ra):

Như vậy chúng ta sẽ có được một hàm có thể cắt và nhận dạng các phần của ảnh đó. Tuy nhiên, để có thể trả về ảnh, mình đã encode những superpixel và decode lại khi xây dựng ứng dụng di động.
Để có thể gọi API ở mọi nơi, mình đã tìm hiểu cách đưa nó lên cloud. Và Google Cloud chính là công cụ mình sử dụng. Dịch vụ Google Cloud này có rất nhiều tính năng đa dạng khác nhau. Và theo nhu cầu cá nhân, mình đã thử 3 công cụ khác nhau đó chính là:
- Compute Engine (tạo một máy ảo có API)
- Cloud Run (deploy API vào Cloud Run)
- Vertex AI (đưa model lên thẳng trên Cloud)
Các bạn có thể tham khảo từ những nguồn này. Dù đã thử tới 3 cách nhưng API của mình hoạt động vẫn không được mượt mà và chính xác. Thế nên mình đã quyết định …… làm local :’) và đưa nó vào phần III (hướng phát triển).
- Tạo ứng dụng di động
Để việc ứng dụng việc sử dụng mô hình nhằm nhận dạng bệnh trên lá cây được thuận tiện và dễ dàng hơn, mình đã tạo một ứng dụng di động có thể chụp hình hoặc lấy ảnh từ thư viện của máy để xử lý và nhận dạng qua API đã được tạo.
Khi xây dựng một ứng dụng, chúng ta sẽ có 3 phương pháp chính:
- Native apps là những ứng dụng được tạo ra cho một nền tảng hay hệ điều hành nhất định (ví dụ: iOS, Android, Linux,…).
- Web apps là những phiên bản có thể được nâng cấp, sửa chữa của các trang web mà chúng có thể chạy được trên mọi thiết bị di động và hệ điều hành.
- Hybrid apps là sự kết hợp giữa Native apps và Web apps, được xây dựng dựa trên các công nghệ web như là HTML, Javascript, CSS và đặc biệt là có thể được phát triển cho hai hệ điều hành như iOS và Android. Trong số đó, React Native là một trong những framework tốt nhất được dùng để xây dựng ứng dụng di động. Hiện nay đã có nhiều ứng dụng nổi tiếng được tạo ra bằng React Native như: Facebook, Skype, Instagram,…
Và mình đã sử dụng React Native để xây dựng ứng dụng. Mọi người có thể tìm hiểu về cách tạo ứng dụng bằng React Native qua video này. Trong ứng dụng, mình đã sử dụng thư viện Expo. Bởi vì Expo có SDK (các bạn có thể tìm hiểu về SDK tại đây) ImagePicker, dùng để truy cập vào camera hoặc thư viện ảnh của máy. Bên cạnh đó, khi sử dụng Expo, chúng ta có thể chạy ứng dụng ngay trên điện thoại trực tiếp bằng ứng dụng Expo Go.
Bên cạnh đó, để có thể gửi request trong React Native, mọi người có thể tham khảo tại đây. Kết quả trả về từ API là một dãy bao gồm các superpixel được cắt ra và kết quả nhận dạng của từng superpixel đó.
Nếu các bạn muốn trải nghiệm thử qua ứng dụng của mình thì hãy nói mình biết nhé :’) mình sẽ fix phần Google Cloud để ai cũng có thể thử qua ứng dụng.
III. Những dự định tiếp theo ở ViSEF (nhưng không được thi ?)
Trong lúc thực hiện đề tài, mình đã có những ý tưởng phát triển và cải tiến cho sản phẩm để có thể được ứng dụng tốt hơn trong đời sống.
Thứ nhất, mình định sẽ xây dựng một hệ thống hỗ trợ giám sát và chăm sóc vườn ngô. Đại khái là mình sẽ tạo một con robot, công việc của nó là sẽ đi quanh vườn vào một khoảng thời gian đã được chọn sẵn (ví dụ: vào mỗi sáng) để xem thử có cây nào bị bệnh không. Bên cạnh đó, ta có thể tích hợp thêm các cảm biến độ ẩm, nhiệt độ, hay độ sáng để cung cấp được nguồn thông tin đa dạng hơn cho người nông dân. Tự động tưới nước, đóng mở mái che dựa vào nguồn dữ liệu được cung cấp cũng là những cách phát triển khá thú vị.
Thứ hai, để mô hình nhận dạng được chính xác hơn, mình định sử dụng phương pháp Semi-Supervised Learning. Phương pháp này đơn giản là sẽ sử dụng model đã được train để phân loại những dữ liệu mới. Sau đó, dùng bộ dữ liệu mới để train lại model. Như vậy, bộ dữ liệu của chúng ta sẽ được cập nhật theo thời gian.
Và cuối cùng, thay vì sử dụng bộ cơ sở dữ liệu có sẵn thì tự chụp ảnh để xây dựng bộ cơ sở dữ liệu phù hợp vẫn là một lựa chọn tốt hơn cho các bài toán nhận dạng. Mặc dù nó sẽ tốn nhiều thời gian hơn nhưng bộ cơ sở dữ liệu càng tốt thì mô hình được huấn luyện càng có độ chính xác cao hơn. Bên cạnh đó, mình cũng có thể mở rộng số lượng bệnh khác nhau để có thể phát hiện được chính xác loại bệnh hơn.
IV. Một số thắc mắc của mình
Trong quá trình thực hiện đề tài, mình cũng có rất nhiều thắc mắc. Một vài trong số đó thì mình cũng đã tự tìm hiểu và tự giải đáp cho mình. Tuy nhiên cũng có vài vấn đề mình cũng chưa biết rõ. Mình xin chia sẻ một số thắc mắc của mình để có cao nhân nào đọc qua thì giải đáp giúp mình với ạ.
Ở phần dự định phát triển, mình có đề cập tới việc sử dụng phương pháp Semi-Supervised Learning để có thể tự nâng cấp, cập nhật bộ cơ sở dữ liệu được đa dạng hơn và phù hợp theo thời gian. Thì phương pháp này sẽ sử dụng model đã được train để nhận dạng và phân loại bộ data mới và train lại theo bộ data mới đó. Thắc mắc thứ nhất của mình là về độ chính xác của phương pháp này. Vì không có model nào là có thể nhận dạng chính xác 100% nên khi sử dụng model đã được train để phân loại (gán nhãn) bộ data mới thì liệu sự sai sót trong việc phân loại đó có khiến model được train bằng data mới bị sai lệch nhiều theo thời gian không? Một sai số nhỏ có thể gây ra sai lệch nhiều sau nhiều lần train lại bằng bộ data mới hay không? (theo mình nghĩ hiện tượng này được gọi là Hiệu ứng cánh bướm/Butterfly effect). Và nếu sẽ gây ảnh hưởng đến việc nhận dạng thì chúng ta có giải pháp nào khác hay không?
Bên cạnh đó, nếu sử dụng phương pháp Semi-Supervised Learning để có thể tự nâng cấp, cập nhật bộ cơ sở dữ liệu thì trong vườn ngô cũng cần phải có một số cây bệnh. Nếu không thì chỉ có dữ liệu của những phần lá khỏe mạnh (healthy) và phông nền (background) được cập nhật. Vậy thì liệu phương pháp này có hiệu quả và cần thiết? Nếu không thì làm sao để có thể cập nhật được bộ dữ liệu một cách tốt nhất?
Đó là một vài thắc mắc của mình. Không biết có bạn nào cũng có những câu hỏi giống mình như này hay không? Nếu ai biết được cách giải quyết hay một hướng khác nào đó thì hướng dẫn cho mình với nha.
V. Nguồn tham khảo
https://www.mathworks.com/discovery/deep-learning.html
https://archive.ics.uci.edu/ml/datasets/wine+quality
https://viblo.asia/p/linear-regression-hoi-quy-tuyen-tinh-trong-machine-learning-4P856akRlY3
https://keras.io/api/applications
https://onlinelibrary.wiley.com/doi/full/10.1002/sam.11583
https://www.v7labs.com/blog/image-segmentation-guide
https://darshita1405.medium.com/superpixels-and-slic-6b2d8a6e4f08
https://www.datarobot.com/wiki/overfitting
https://viblo.asia/p/api-la-gi-nhung-diem-ban-can-hieu-ro-gGJ59x9DlX2
https://viblo.asia/p/restful-api-la-gi-1Je5EDJ4lnL
https://cloud.google.com/products
https://reactnative.dev/docs/getting-started
Xin chào, không biết có được bao nhiêu bạn đọc được từ đầu đến đây ta? Cũng khá dài ha :’). Mình xin cảm ơn mọi người đã quan tâm đến bài chia sẻ của mình. Nếu có câu hỏi hay thắc mắc gì thì mình sẽ giải đáp (nếu có khả năng :>). Và nếu bạn nào có thể thì giáp đáp những thắc mắc của mình với nhá :))). Cảm ơn mọi người rất nhiều!
4,603 total views, 5 views today